Doc Analyzer Reinvented: Goodbye Gradio and ChromaDB, Hello Qdrant and Streaming
Every project eventually reaches the point where it has accumulated enough technical debt to force a choice: patch it or redo it? With Doc Analyzer I chose the second option. Four times in a row, one major version after another.
If you haven’t run into it before: Doc Analyzer is my open source project for analyzing documents using a completely local AI — no cloud, no API keys, no data flowing through someone else’s servers. This post covers what happened from version 0.2.0 to 0.5.0, which amounts to a near-total rewrite.
Deep breath. Let’s start from the beginning.
Goodbye LangChain and ChromaDB (v0.2.0)
The first thing I threw out was the LangChain + ChromaDB combo. Not because they were bad choices at the time — LangChain was the go-to RAG framework and ChromaDB did the job — but both shared a common problem: too much magic under the hood.
LangChain in particular has evolved into one of those frameworks where doing something simple requires traversing five layers of abstraction, figuring out which version of the API you’re actually using, and hoping yesterday’s update didn’t break anything. I decided to drop it and implement exactly what I needed: a custom Document dataclass and a hand-rolled RecursiveCharacterTextSplitter. Nothing fancy, but at least I know exactly what it does.
In place of ChromaDB, I brought in Qdrant, using cosine distance and 1024-dimension vectors. The reason for the migration is simple: Qdrant has a cleaner API, more predictable persistence handling, and — not a minor detail — a Python client that behaves the way you’d expect.
The other big change in this version is model separation: there’s now a dedicated EMBEDDING_MODEL (mxbai-embed-large), separate from the LLM used to generate responses. Before, everything ran on the same model, which worked but was a bit like using a hammer both to drive nails and to peel oranges.
Goodbye Gradio (v0.3.0)
This is the change that gave me the most personal satisfaction. Gradio was fine for quick prototypes, but it had a set of behaviors that drove me up the wall:
- SSE (Server-Sent Events) for streaming had random drops
BodyStreamBuffer abortedwould show up in the logs for no apparent reason- The page would reset mid-inference
- Every Gradio update was a game of Russian roulette with backward compatibility
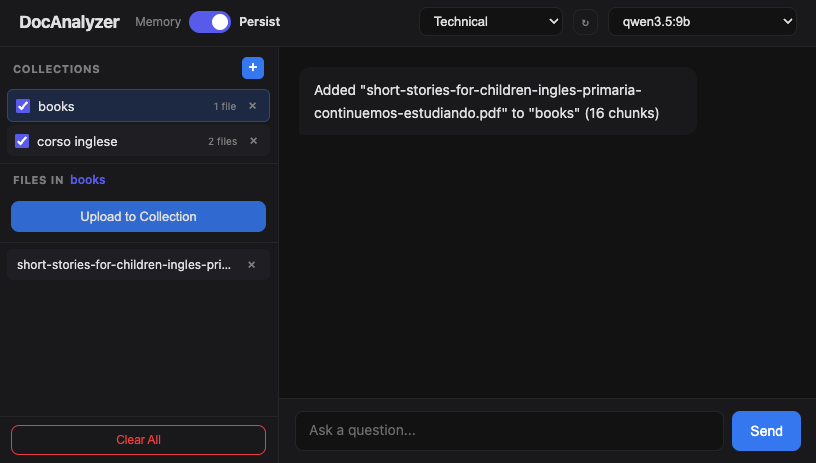
I rewrote the interface in vanilla HTML/JS, served by FastAPI as a FileResponse pointing to templates/index.html. Zero frontend dependencies. Zero npm. Zero CDN. It works.
The layout is sidebar + chat with a dark theme, fully responsive. The textarea auto-resizes, submits with Enter (Shift+Enter for a newline, like a human being), and the send button automatically disables when no documents are loaded — a small UX detail that makes a huge practical difference.
What ultimately pushed me to make this move was LLM response streaming. With Gradio it was a constant battle. Now there’s a dedicated POST /api/query/stream endpoint with real SSE: tokens arrive progressively with a blinking cursor while the model generates, and Markdown renders in real time during streaming. Watching code blocks form token by token as the model responds is one of those moments that reminds you why you do this job.
Also in this version: OCR fallback for scanned or vector-path PDFs. If PyMuPDF can’t extract text from a page, the system renders it at 300 DPI and runs pytesseract over it. Automatic, transparent, silent.
Multi-Collection with Memory/Persist Toggle (v0.4.0)
This version introduced a feature many people had asked for: separate collections with a Memory/Persist toggle directly in the interface, no .env file changes required.
The basic idea is that documents can be organized into themed collections — by project, by type, by client, by whatever makes sense to you. You can create and delete collections from the sidebar, choose which collection to use as the upload target, and select via checkboxes which collections to include in a query.
When querying across multiple collections, results are merged and re-ranked by cosine similarity score, keeping the top 4 globally. The model has no idea it’s querying multiple collections — it only sees the most relevant context, regardless of where it came from.
The Memory/Persist toggle deserves a quick explanation:
Memory mode (default): Qdrant runs entirely in memory, same as before. Fast, zero configuration, data lost on restart. Perfect for quick analysis sessions.
Persist mode: Qdrant saves to disk, data survives container restarts. When switching from Memory to Persist, the files_map is automatically rebuilt from Qdrant payloads — nothing to do manually.
Switching modes from the header button is instant. No restart, no configuration change.
Architectural Refactoring and Prompt System (v0.5.0)
The last version is the one I’m most satisfied with technically, even if it’s the least visible from the outside. The main theme: eliminate global state and separate responsibilities.
The Service Layer
I extracted a DocumentService (src/services/document_service.py) that centralizes all document state and business logic. Before, app.py had turned into a blob with mutable global variables, global keywords scattered around, and loose helper functions floating without a home.
Now the FastAPI routes are thin HTTP adapters that delegate to the service. They know nothing about Qdrant, they don’t handle files, they hold no state. They receive a request, call the service, return a response. As it should be.
Dependency Injection in RAGProcessor
The RAGProcessor previously read its configuration from environment variables at construction time. This made tests a nightmare: you had to monkeypatch env vars, patch clients, and hope the import order didn’t break everything.
Now the constructor accepts ollama_client and qdrant_client injected directly. For production there’s the RAGProcessor.from_env() classmethod that does what it used to do. For tests, you pass MagicMock() objects and you’re done. 92 tests, zero global state, zero client patching.
The Rewritten ProcessorFactory
The original factory was an if/elif chain that violated the Open/Closed Principle in the most textbook way possible: to add a format, you had to modify the factory.
Now there’s a _PROCESSOR_MAP: dict[str, type[DocumentProcessor]]. Adding support for a new format is literally one line:
_PROCESSOR_MAP = {
".pdf": PdfProcessor,
".docx": WordProcessor,
".txt": TextProcessor,
# adding a format = adding a line here
}
The Prompt System with Auto-Discovery
The last change is about analysis roles. Before, they were defined as a hardcoded dictionary in Python. Adding a role meant modifying code, making a commit, restarting the server.
Now roles live as .md files in src/prompts/. The PromptRegistry auto-discovers them via glob("*.md"), parsing the first # Heading as the display name and the filename stem as the API key. Adding a role means creating a file in this format:
# My Custom Role
You are an expert in [domain]. When analyzing documents,
focus on [specific aspects] and always respond in [tone].
Then press the ↻ button in the header to hot-reload prompts, no server restart needed. No code changes.
How to Upgrade
If you’re on a previous version, upgrading is a pull + rebuild:
git pull origin main
docker compose up --build -d
Pay attention to the configuration: the .env file now requires EMBEDDING_MODEL separate from LLM_MODEL:
LLM_MODEL=qwen2.5:14b
EMBEDDING_MODEL=mxbai-embed-large:latest
OLLAMA_HOST=localhost # Docker automatically overrides this with host.docker.internal
OLLAMA_PORT=11434
QDRANT_DB_PATH=./data/qdrant
CHUNK_SIZE=1000
CHUNK_OVERLAP=200
Pull the required models in Ollama:
ollama pull mxbai-embed-large # required for embeddings
ollama pull qwen2.5:14b # or any LLM you prefer
Where We Are Now
Looking at the project today, it’s hard to recognize it compared to the initial version. The architecture is completely different, the stack has changed almost entirely, and the interface was rewritten from scratch. Yet the founding principle hasn’t moved an inch: all your data stays on your machine, full stop.
No cloud, no API keys, no hidden telemetry, no monthly subscriptions. Your document stays yours.
If you want to look at the code, ask a question, or open a PR, the repository is on GitHub. Contributions are always welcome, especially if they come with tests.