Doc Analyzer: Supporto Multi-formato e Interfaccia Avanzata per la Tua IA Locale
Ciao a tutti! Sono tornato per parlarvi degli aggiornamenti di Doc Analyzer, il nostro progetto di analisi documentale basato su IA che mantiene tutti i vostri dati al sicuro, in locale.
Negli ultimi giorni ho implementato così tante nuove funzionalità che Doc Analyzer potrà sembrarvi praticamente uno strumento praticamente nuovo. Vediamo insieme tutte le novità!
Supporto Multi-formato: Da TXT a Dockerfile
La novità più importante di questo aggiornamento è l’espansione dei formati supportati. Doc Analyzer non è più limitato a PDF e documenti Word, ma ora può analizzare praticamente qualsiasi tipo di file testuale! E la cosa ancora più interessante è che ora puoi aggiungere (e rimuovere) più file contemporaneamente al contesto, superando la precedente limitazione di poter analizzare un solo documento alla volta. Questo è un vero game-changer per analisi complesse che richiedono l’integrazione di informazioni da fonti diverse.
File di Testo Semplice (.txt)
Partiamo dalle basi: i file TXT sono ovunque, dai log di sistema alle note rapide, e sono spesso ricchi di informazioni preziose. Doc Analyzer ora li gestisce nativamente, permettendoti di estrarre conoscenza anche dai tuoi documenti più basilari.
L’implementazione è stata relativamente semplice grazie alla nostra architettura modulare. Il nuovo TextProcessor si integra perfettamente con il nostro sistema di factory, riconoscendo automaticamente i file .txt e processandoli in modo ottimale per l’analisi.
File RTF: Quando il Formato Conta
I file Rich Text Format (RTF) rappresentano un interessante caso intermedio tra i semplici file di testo e i documenti Word completi. Utilizzando la libreria textract, il nuovo RtfProcessor è in grado di preservare la formattazione importante durante l’estrazione del testo, mantenendo così il contesto necessario per una corretta analisi.
Codice, Markdown e Persino i Dockerfile (con qualche accorgimento..)
Questa è probabilmente la funzionalità più attesa dagli sviluppatori! Doc Analyzer ora supporta l’analisi di file di codice in praticamente qualsiasi linguaggio di programmazione: Python, JavaScript, Java, C/C++, PHP e molti altri.
Il nuovo CodeProcessor è stato progettato per riconoscere automaticamente il linguaggio di programmazione in base all’estensione del file.
Questo significa che puoi caricare un intero file sorgente e fare domande come:
- “Quali sono le principali funzionalità implementate in questo codice?”
- “Ci sono potenziali bug o vulnerabilità di sicurezza?”
- “Come potrei migliorare l’efficienza di questa funzione?”
Se sei nel mondo tech, probabilmente lavori quotidianamente con file Markdown (.md) e YAML (.yml/.yaml). Questi formati sono diventati lo standard per la documentazione e la configurazione, quindi era fondamentale supportarli nativamente.
Una piccola grande novità è il supporto per i Dockerfile, quei file senza estensione che definiscono le configurazioni dei container Docker. C’è un piccolo trucco: dato che Gradio (la nostra interfaccia UI) ha alcune limitazioni con i file senza estensione, dovrai rinominare il tuo Dockerfile aggiungendo un’estensione (es. Dockerfile.txt) prima di caricarlo. Ma non preoccuparti, il sistema è abbastanza intelligente da riconoscerlo automaticamente in base al contenuto!
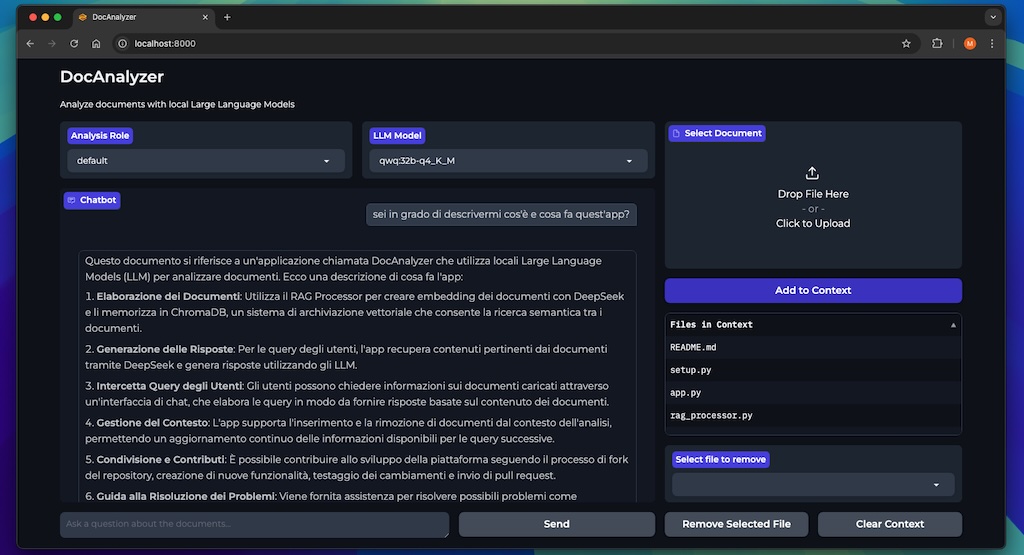
Selezione del Modello LLM: La Potenza della Scelta
Una delle novità più significative è la possibilità di selezionare quale modello di intelligenza artificiale utilizzare per l’analisi dei documenti. Prima eravamo vincolati al modello specificato nell’ambiente, tipicamente DeepSeek R1, ma ora puoi scegliere tra tutti i modelli installati nel tuo Ollama!
L’interfaccia ora include un menu a tendina che mostra automaticamente tutti i modelli disponibili sul tuo sistema. Questo significa che puoi:
- Passare a un modello più leggero quando hai bisogno di risposte rapide
- Utilizzare un modello più potente per analisi complesse
- Scegliere modelli specializzati per compiti specifici (codice, documenti legali, analisi scientifica, ecc.)
È stato necessario modificare profondamente la classe RAGProcessor per supportare questa funzionalità. Ora il metodo query() accetta un parametro opzionale model che permette di specificare quale modello utilizzare per generare la risposta, mentre la connessione a Ollama viene utilizzata per recuperare la lista di modelli disponibili.
def get_available_models(self):
try:
response = requests.get(f"http://{os.getenv('OLLAMA_HOST', 'localhost')}:{os.getenv('OLLAMA_PORT', '11434')}/api/tags")
if response.status_code == 200:
models = [model["name"] for model in response.json()["models"]]
return models
return []
except Exception as e:
logger.error(f"Error fetching available models: {str(e)}")
return []
Inoltre, abbiamo aggiunto una validazione per “fallire” rapidamente quando la variabile d’ambiente LLM_MODEL non è configurata, garantendo un’esperienza più fluida e chiare indicazioni di errore quando qualcosa non va.
Gestione Avanzata del Contesto Documentale
Un’altra novità è il miglioramento della gestione del contesto documentale. Prima, visualizzavamo semplicemente un elenco di file caricati in una casella di testo, ora abbiamo:
Visualizzazione tabellare: Abbiamo sostituito la semplice casella di testo con una tabella dataframe che mostra chiaramente ogni documento nel contesto, rendendo molto più facile tenere traccia dei file che stai analizzando.
Rimozione selettiva di documenti: La funzionalità che cambia davvero le carte in tavola! Prima, se volevi rimuovere un documento dal contesto, dovevi eliminare l’intero database vettoriale e ricominciare da capo. Ora puoi selezionare specifici documenti da rimuovere mantenendo il resto del contesto intatto.
def remove_document(self, document_id):
"""Remove a specific document from the vector database by ID."""
if self.vectordb is None:
return False
try:
# Remove the document from the collection
self.vectordb._collection.delete(document_id)
return True
except Exception as e:
logger.error(f"Error removing document: {str(e)}")
return False
Per supportare questa funzionalità, abbiamo sostituito la semplice lista processed_files con un dizionario processed_files_map che tiene traccia degli ID dei documenti nel database vettoriale. Questo ci permette di identificare e rimuovere documenti specifici senza influenzare gli altri.
Interfaccia Utente Migliorata
L’interfaccia utente ha ricevuto un significativo aggiornamento per supportare tutte queste nuove funzionalità:
- Il contesto dei documenti è ora visualizzato in una tabella dataframe
- Un nuovo menu a tendina per la selezione del modello LLM
- Controlli per la rimozione selettiva dei documenti
- Supporto per più formati di file nell’uploader
Questi cambiamenti non solo migliorano l’estetica dell’applicazione, ma rendono anche l’esperienza utente molto più fluida e intuitiva. La visualizzazione tabellare, in particolare, offre un colpo d’occhio immediato su quali documenti sono attualmente disponibili per l’analisi.
Privacy e Sicurezza: Sempre al Primo Posto
Nonostante tutte queste nuove funzionalità, Doc Analyzer mantiene il suo impegno fondamentale per la privacy e la sicurezza. Tutti i dati rimangono sul tuo computer, tutti i processi avvengono in locale, e nessuna informazione viene mai condivisa con servizi cloud esterni.
Le nuove funzionalità per la gestione del contesto offrono anche vantaggi in termini di sicurezza: rimuovendo selettivamente i documenti sensibili quando non sono più necessari, riduci la finestra di esposizione dei dati anche all’interno del tuo sistema locale.
Come Aggiornare e Iniziare a Usare le Nuove Funzionalità
Se non vedi l’ora di provare tutte queste nuove funzionalità, ecco come fare:
- Aggiorna il tuo repository:
git pull origin main
- Assicurati di avere Ollama installato con almeno un modello:
ollama pull deepseek-r1:14b # o qualsiasi altro modello
- Aggiorna il tuo file .env per includere esplicitamente il modello LLM:
OLLAMA_HOST=host.docker.internal # o localhost per sviluppo locale
OLLAMA_PORT=11434
CHROMA_DB_PATH=/app/data/chroma
LLM_MODEL=deepseek-r1:14b # Ora obbligatorio!
CHUNK_SIZE=1000
CHUNK_OVERLAP=200
PERSIST_VECTORDB=false
- Riavvia l’applicazione:
docker compose up -d
Uso Pratico: Un Esempio Concreto
Per illustrare la potenza di queste nuove funzionalità, ecco uno scenario d’uso reale:
Immagina di dover analizzare un progetto software complesso. Prima, saresti stato limitato ad analizzare un solo documento alla volta, rendendo difficile collegare informazioni tra file diversi. Ora puoi caricare contemporaneamente:
- La documentazione tecnica in PDF
- I file di codice sorgente
- I file di configurazione YAML
- I Dockerfile
Tutti questi documenti possono essere aggiunti al contesto insieme, creando un corpus di conoscenza integrato che il modello IA può consultare simultaneamente.
Tutto questo entra a far parte di un unico contesto che Doc Analyzer può interrogare in modo intelligente. Puoi chiedere:
“Come è implementata la funzione di autenticazione in questo sistema e quali sono le configurazioni di sicurezza correlate?”
Doc Analyzer analizzerà sia il codice che la documentazione, collegando le informazioni in modo coerente per darti una risposta completa che tenga conto di tutte le fonti.
Inoltre, puoi scegliere il modello più adatto alla tua domanda. Per questioni di codice, potresti preferire un modello ottimizzato per la programmazione; per analisi documentali generiche, un modello più bilanciato potrebbe essere più appropriato.
Il Futuro di Doc Analyzer
Queste nuove funzionalità rappresentano un passo importante nell’evoluzione di Doc Analyzer, ma non ci fermiamo qui. Stiamo già lavorando a:
- Supporto per ancora più formati di file
- Miglioramenti nella tokenizzazione per un’analisi ancora più precisa
- API REST completa per l’integrazione con altri strumenti
- Sistema di caching avanzato per risposte più rapide su documenti analizzati frequentemente
Il nostro obiettivo è creare il miglior strumento possibile per l’analisi documentale basata su IA, mantenendo sempre i dati sicuri e sotto il tuo controllo.
Contribuire al Progetto
Doc Analyzer è un progetto open source, e siamo sempre entusiasti di ricevere contributi dalla community. Se hai idee per nuove funzionalità, hai trovato bug da correggere o vuoi semplicemente dare un’occhiata al codice, visita il repository GitHub.
Abbiamo una struttura di progetto ben organizzata e una documentazione dettagliata che rende facile iniziare a contribuire, anche se non sei familiare con il progetto.
Conclusione
Con il supporto per nuovi formati, la selezione flessibile del modello LLM e la gestione avanzata del contesto, Doc Analyzer è diventato uno strumento davvero potente per chiunque abbia bisogno di estrarre conoscenza dai propri documenti senza compromettere la privacy.
Come sempre, sono ansioso di sentire le vostre esperienze con queste nuove funzionalità. Quali formati di file trovate più utili? Quali modelli funzionano meglio per i vostri casi d’uso? Fatemi sapere nei commenti!
Risorse utili: