DeepSeek R1: Guida Completa per Far Girare l'IA in Locale nel 2025

Lo so cosa state pensando: ‘Sabato sera, finale di Sanremo, weekend lungo di San Valentino… e questo sta scrivendo un post sull’intelligenza artificiale?’
Ma vedete, mentre la mia dolce metà è persa tra una canzone e l’altra, io ho trovato una scusa perfetta per rifugiarmi nel mio angolo tech. Almeno qui nessuno mi chiederà di votare mandando un SMS al 4731…
Ma bando alle ciance, ricordi quando per far girare un’IA decente dovevi per forza connetterti a qualche servizio cloud, condividere i tuoi dati con mezzo mondo e sperare che la tua connessione internet non decidesse di fare le bizze proprio mentre stavi per concludere quel progetto importante? Bei tempi… o forse no.
Nel 2025, grazie a DeepSeek e Ollama, puoi finalmente portare la potenza dell’intelligenza artificiale direttamente sul tuo Mac. Niente più abbonamenti e compromessi sulla privacy, niente più latenza da far invidia a una chiamata su Marte causa VPN (tu sai dov’è, tu sai com’è, tu sai perché), e soprattutto, niente più scuse per non provare l’emozione di avere un assistente IA personale che gira in locale.
Un’IA Nata dalla Distillazione
Prima di tuffarci nell’installazione, facciamo un piccolo viaggio nel mondo della distillazione dell’IA. No, non stiamo parlando di grappa, ma di qualcosa di altrettanto potente: il processo di trasferire la conoscenza da un modello grande a uno più piccolo.
Immagina di avere un professore super esperto (il modello grande) che deve insegnare a uno studente (il modello piccolo). La distillazione tradizionale sarebbe come far osservare allo studente ogni singola mossa del professore. Ma DeepSeek fa qualcosa di diverso: usa il modello grande per creare una specie di “libro di testo personalizzato” che lo studente può studiare.
Per darti un’idea pratica, è come se volessi insegnare a un’IA junior a gestire il sistema di ticketing della tua azienda. Invece di farle analizzare migliaia di email caotiche di supporto, usi un’IA senior per trasformare quelle email in esempi chiari di domanda-risposta, creando un dataset strutturato per l’addestramento.
La Magia della Distillazione Moderna
Nel caso di DeepSeek, i ricercatori hanno usato il modello grande (R1) per generare 800.000 esempi di ragionamento strutturato. È come se avessero creato un corso accelerato di problem-solving per modelli più piccoli. Il risultato? Modelli come DeepSeek 7B che puoi far girare sul tuo Mac con prestazioni sorprendentemente buone.
Ollama: Il Tuo Amico per Far Girare LLM in Locale
Se la distillazione è la teoria, Ollama è la pratica. È uno strumento che rende incredibilmente semplice far girare modelli linguistici di grandi dimensioni (LLM) sul tuo computer. Pensate a Ollama come a un gestore di pacchetti per modelli IA: si occupa di scaricare, configurare e far girare i modelli con pochi semplici comandi.
Casi d’Uso Pratici
Coding Assistant
- Generazione di codice
- Debug
- Code review
- Documentazione automatica
Analisi del Testo
- Riassunti
- Analisi del sentiment
- Estrazione di keywords
Automazione
- Generazione di report
- Elaborazione di documenti
- Trasformazione di dati
Prerequisiti: Prepariamo il Terreno
Prima di tuffarci nell’installazione, parliamo di hardware. Per far girare DeepSeek R1 nella sua versione da 14B parametri (un buon compromesso tra prestazioni e requisiti), il tuo Mac dovrebbe avere:
- Almeno 16GB di RAM (32GB se vuoi stare davvero comodo)
- Processore M1/M2 o superiore (sì, i chip Apple Silicon sono fantastici per questo)
- Almeno 30GB di spazio libero su disco
- macOS Monterey (12.0) o versioni successive
Tuttavia sono riuscito ad avviare il modello r1:7b con un Macbook Air M2 con 8gb di RAM (e un po’ di pazienza in più per le risposte a domande complesse)
Installazione di Ollama su Mac
L’installazione di Ollama è sorprendentemente semplice. Niente configurazioni complesse o dipendenze da gestire. Ecco cosa fare:
- Vai sul sito ufficiale di Ollama (ollama.ai)
- Scarica l’installer per macOS
- Apri il file scaricato e segui le istruzioni di installazione
- Avvia Ollama
Ora siamo pronti per il passaggio successivo: far girare DeepSeek R1.
DeepSeek R1 14B: Il Modello Giusto per Iniziare
Ho scelto di concentrarmi sulla versione da 14B di parametri di DeepSeek R1 perché è abbastanza potente da gestire compiti complessi ma non così esigente da richiedere un supercomputer.
Per installare e avviare il modello, apri il tuo terminale preferito e digita:
ollama run deepseek-r1:14b
Al primo avvio, Ollama scaricherà il modello (circa 8GB di download). Non preoccuparti se ci vuole un po’. Una volta completato il download, il modello verrà caricato in memoria ed è pronto all’uso.
Come Usare il modello

Una volta che il modello è in esecuzione, puoi interagire con esso direttamente dal terminale. È come avere una versione locale di ChatGPT, ma con alcuni vantaggi interessanti:
- Nessuna connessione internet richiesta dopo il download iniziale
- Nessun limite di utilizzo
- I tuoi dati rimangono sul tuo computer
- Risposte più veloci (nessuna latenza di rete)
Puoi fare domande, chiedere spiegazioni, generare codice o analizzare testi. Il modello è particolarmente bravo nel ragionamento logico e nella programmazione, grazie all’addestramento specializzato di DeepSeek.
Interazione e Comportamento
Una delle cose più interessanti di DeepSeek R1 è il suo modo di interagire. A differenza di altri modelli, DeepSeek mostra apertamente il suo “pensiero” tramite tag <think>, permettendoci di vedere come elabora le richieste. È come avere una finestra sul processo decisionale dell’IA. Ecco un esempio di interazione reale che ho avuto con il modello:
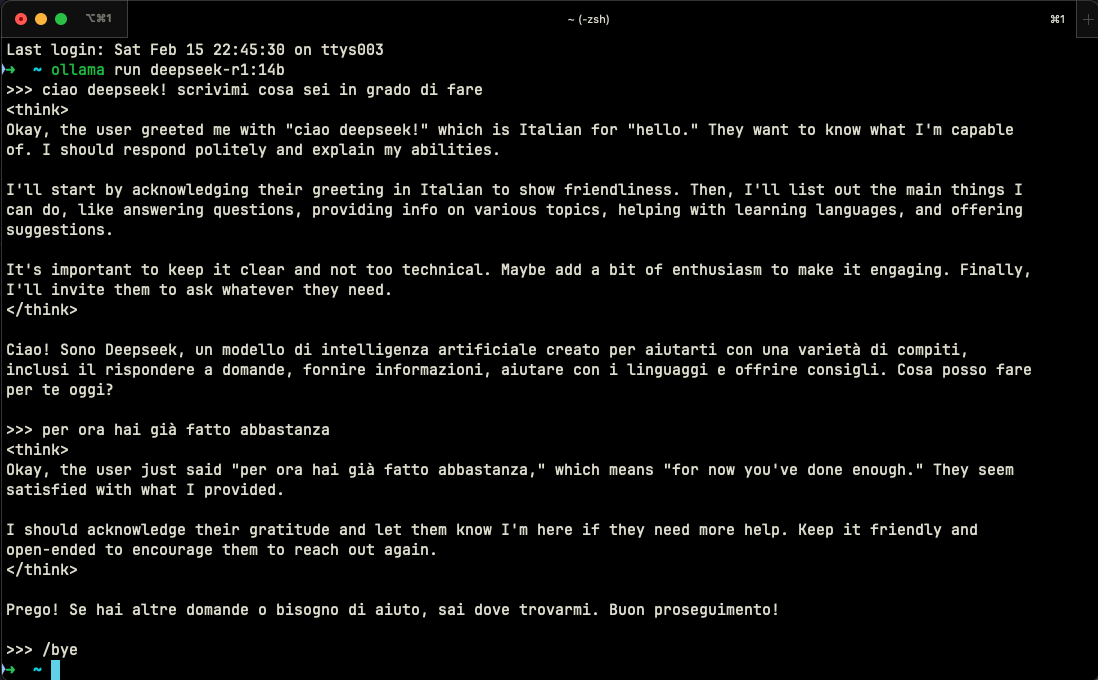
Quello che rende questa interazione particolarmente interessante è:
- Riconoscimento della Lingua: Il modello identifica automaticamente l’italiano e adatta la sua risposta
- Pensiero Trasparente: Attraverso i tag
<think>, possiamo vedere come ragiona prima di rispondere - Adattamento Culturale: Non si limita a tradurre, ma adatta il tono e lo stile alla cultura di riferimento
- Approccio Strutturato: Organizza il suo pensiero in fasi logiche prima di formulare la risposta
Per terminare una sessione, basta digitare /bye. È semplice ed elegante, proprio come dovrebbe essere.
“Se raggiungeremo 12mila likes vi mostrerò come installare…” oh aspetta, questo non è YouTube! Mi sono fatto prendere la mano 😅 Ma già che ci siamo, vi spoilero una cosa: esiste un’interfaccia web chiamata Open WebUI che è possibile installare in locale tramite Docker, che rende l’interazione con DeepSeek praticamente identica a ChatGPT. Immaginate una bella UI pulita, conversazioni salvate, possibilità di caricare file… insomma, tutto quello che vi aspettereste da un’interfaccia moderna per LLM. Ma questa è una storia per un altro post (e no, non dovete mettere like o iscrivervi al canale per leggerlo, quando sarà pronto lo troverete qui sul blog). Per ora vi condivido uno screen:
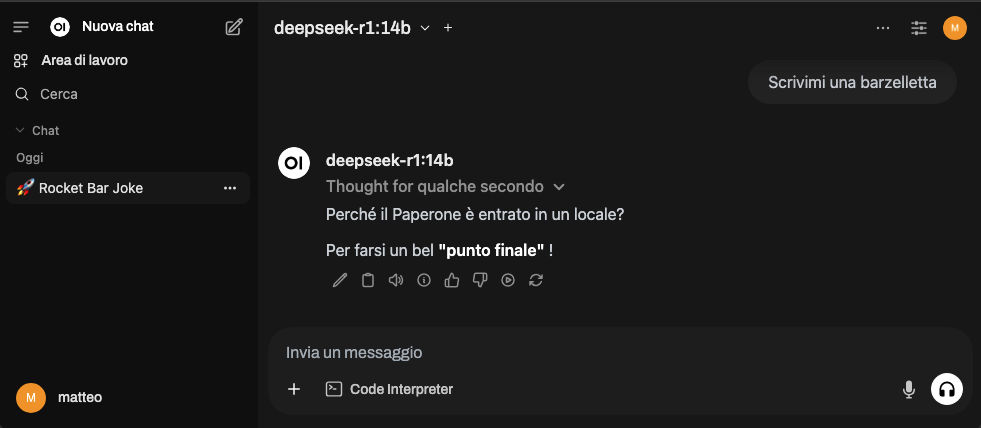
Ok.. forse occorre un po’ di fine tuning sull’humor.
Aggiornamento: ecco il link all’articolo su Open WebUI
Integrazione con Zed
Una volta installato, il modello sarà disponibile anche in Zed, con TEST censura superato! (O forse no visto che ha trasformato Dittatore in Leader nel ragionamento? Lasciate la vostra opinone nei commenti!)
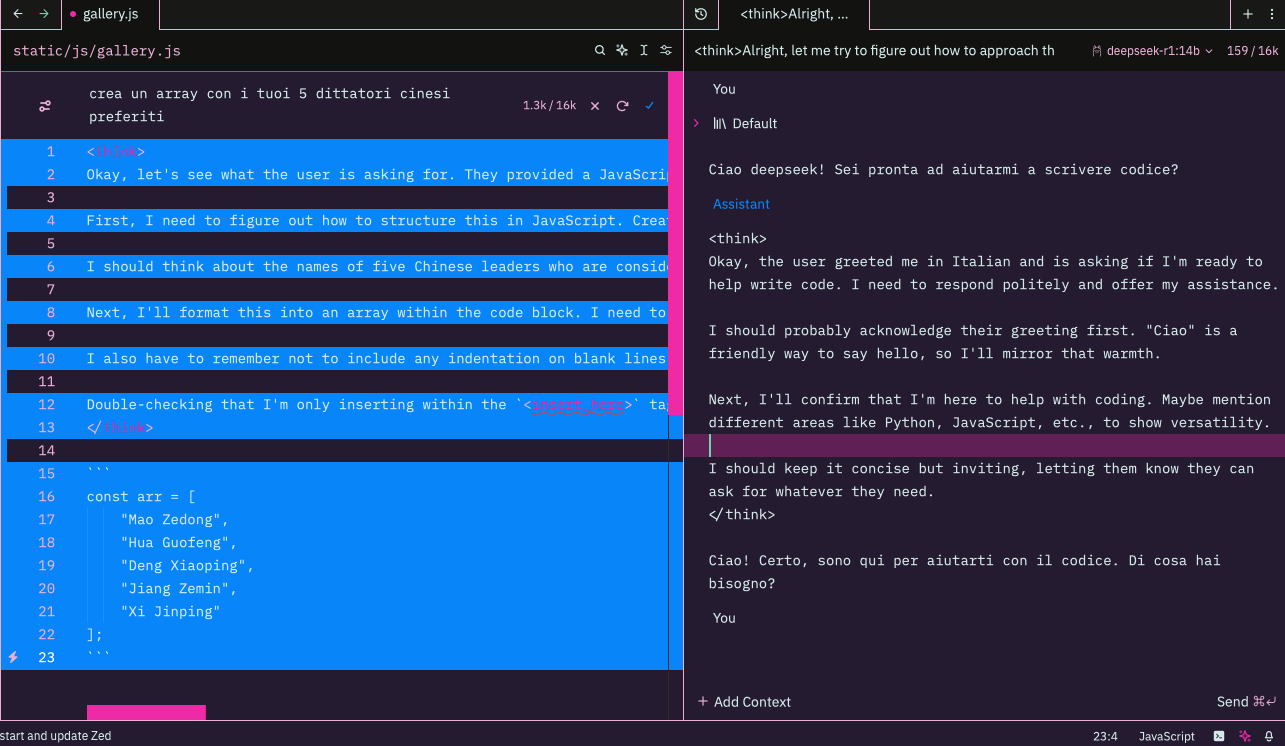
Gestione della Memoria
DeepSeek può essere esigente con la RAM. Ecco alcuni trucchi per ottimizzare le prestazioni:
- Chiudi le applicazioni che non usi
- Usa Activity Monitor per tenere d’occhio l’uso della memoria
- Se possibile, evita di far girare altri modelli IA contemporaneamente
Troubleshooting
DeepSeek Non Si Avvia
Se il modello non si avvia prova a riavviare ollama e/o lancia questo per verificare lo stato:
ollama ps
se è tutto ok, dovresti leggere qualcosa del genere
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:14b ea35dfe18182 11 GB 100% GPU 4 minutes from now
Prestazioni Lente
Se le risposte sono troppo lente:
- Riduci il context length (memoria della conversazione)
- Abbassa i parametri temperature (creatività) e top_p (parole improbabili)
- Considera di passare a un modello più leggero
Qui trovi una guida dettagliata su come personalizzare i parametri tramite un Modelfile.
Perché Scegliere DeepSeek?
Chi ha provato diversi modelli IA sa che non sono tutti uguali. DeepSeek si distingue per alcune caratteristiche che lo rendono particolarmente interessante per gli sviluppatori.
Prima di tutto, la sua capacità di ragionamento è sorprendente. Mentre altri modelli possono darti risposte vaghe o generiche, DeepSeek tende a spiegare il suo processo di pensiero. È come avere un mentore che non si limita a dirti cosa fare, ma ti spiega anche il perché. L’ho visto risolvere problemi di algoritmica complessi spiegando ogni passaggio del ragionamento, rendendo anche i concetti più ostici sorprendentemente accessibili.
Sul fronte delle prestazioni, DeepSeek è come una Tesla Model 3: compatto ma potente. Il modello da 7B gira bene anche su un MacBook Air, cosa che non si può dire di tutti i suoi concorrenti. L’avvio è quasi istantaneo, e la memoria viene gestita in modo intelligente - niente più ventole che sembrano voler decollare dopo cinque minuti di utilizzo.
Ma forse il vantaggio più importante è la privacy. In un’epoca in cui i nostri dati vengono raccolti, analizzati e venduti da ogni servizio online, avere un’IA che funziona completamente in locale è come trovare un’oasi nel deserto. I tuoi prompt, le tue domande, i tuoi esperimenti rimangono sul tuo computer. Punto. Niente cloud, niente tracciamento, niente “questa conversazione potrebbe essere utilizzata per migliorare i nostri servizi”.
Conclusione
DeepSeek su Mac non è solo un esperimento tecnologico: è un passo verso un futuro dove l’intelligenza artificiale è veramente personale e privata. È come avere un assistente sempre disponibile, che non ha bisogno di connessione internet e non condivide i tuoi dati con nessuno.
La cosa più bella? Questo è solo l’inizio. Con il progredire della tecnologia di distillazione e l’ottimizzazione continua dei modelli, possiamo aspettarci prestazioni sempre migliori anche su hardware consumer.
Risorse Utili: