Llama 4: Tra Promesse e Realtà

Bentornati sul blog! Innanzitutto, mi scuso per la mia assenza nelle ultime settimane: il lavoro mi ha letteralmente sommerso e il tempo per scrivere è diventato un lusso raro. Ma ci sono eventi nel mondo tech che non posso proprio ignorare, e il lancio di Llama 4 è sicuramente uno di questi.
Il 5 aprile 2025, Meta ha finalmente tolto il velo sui tanto attesi modelli Llama 4, annunciando quella che ha definito “l’inizio di una nuova era di intelligenza multimodale”. Ma a qualche giorno dal rilascio, mentre la polvere dell’annuncio inizia a posarsi, è il momento di chiederci: questi nuovi modelli rappresentano davvero la rivoluzione promessa o è tutto fumo negli occhi?
In questo articolo metterò a confronto i dati ufficiali con i test indipendenti, analizzando in profondità l’architettura innovativa e i reali punti di forza e debolezza di questi modelli. Spoiler: la realtà potrebbe essere molto diversa dal marketing.
I Tre Moschettieri: Scout, Maverick e Behemoth
Meta ha presentato tre modelli nella famiglia Llama 4, ognuno con caratteristiche e obiettivi specifici:
Llama 4 Scout: Il modello “leggero” con 17 miliardi di parametri attivi (109 miliardi totali), dotato di 16 esperti e una context window monstre di 10 milioni di token.
Llama 4 Maverick: La versione intermedia con sempre 17 miliardi di parametri attivi ma ben 128 esperti, per un totale di 400 miliardi di parametri. Offre una context window di 1 milione di token.
Llama 4 Behemoth: Il gigante non ancora rilasciato, con 288 miliardi di parametri attivi (16 esperti) e circa 2 trilioni di parametri totali. Utilizzato come “insegnante” per la distillazione degli altri modelli.
A prima vista, questi numeri sembrano impressionanti. Meta afferma che Llama 4 Maverick batte GPT-4o e Gemini 2.0 Flash “su un’ampia gamma di benchmark ampiamente riportati”, mentre Behemoth supererebbe addirittura GPT-4.5, Claude Sonnet 3.7 e Gemini 2.0 Pro su diversi benchmark STEM.
Ma le cose non sono così semplici come sembrano.
L’Architettura MoE: Il Segreto Dietro Llama 4
Prima di entrare nei benchmark, è importante capire cosa rende questi modelli così diversi dai loro predecessori. La vera novità di Llama 4 è l’uso dell’architettura Mixture of Experts (MoE), o “Miscela di Esperti” in italiano.
Ma cos’è esattamente un’architettura MoE? Immaginate un’azienda con vari reparti specializzati. Quando arriva un cliente, un receptionist (il “router”) valuta le sue esigenze e lo indirizza al reparto più adatto. Il cliente interagisce solo con gli specialisti necessari, non con l’intera azienda.
Nello stesso modo, in un modello MoE, non tutti i parametri si attivano per elaborare ogni token di input. Invece, un componente chiamato “router” analizza l’input e dirige ogni token verso specifici “esperti” (sottoreti specializzate) all’interno del modello. Questo approccio è brillante: consente di avere modelli enormi in termini di parametri totali, ma relativamente leggeri ed efficienti durante l’uso, poiché solo una frazione dei parametri viene effettivamente attivata per ogni input.
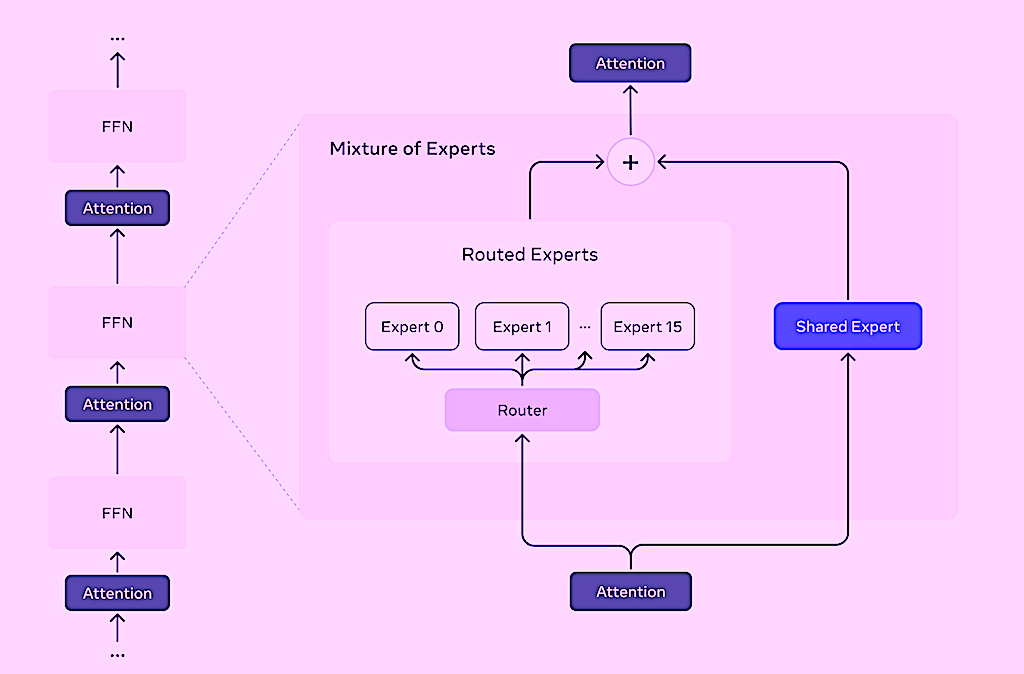
Llama 4 utilizza un’architettura che alterna livelli densi tradizionali e livelli MoE. Ogni token viene inviato sia a un esperto condiviso (comune a tutti i token) sia a uno degli esperti specializzati scelto dal router. Nel caso di Maverick, ci sono 128 esperti specializzati tra cui il router può scegliere.
Questo design è elegante in teoria: permette di avere l’equivalente di 128 mini-modelli specializzati pur mantenendo un costo computazionale ragionevole durante l’inferenza. Ma come vedremo, l’implementazione pratica ha presentato delle sfide.
I Benchmark Ufficiali vs La Realtà dei Test Indipendenti
Qui è dove la storia inizia a complicarsi. Meta ha pubblicato risultati impressionanti per i suoi modelli, specialmente per Behemoth: 95.0 su MATH-500, 82.2 su MMLU Pro, e 73.7 su GPQA Diamond.
Per Maverick, Meta riporta risultati superiori a GPT-4o e Gemini 2.0 Flash su una serie di benchmark di ragionamento, coding e comprensione di immagini. Per Scout, sostiene che superi tutti i precedenti modelli Llama e sia competitivo con Gemma 3.
Ma i test indipendenti raccontano una storia diversa.
Nei benchmark condotti da ricercatori indipendenti, Llama 4 Maverick si è posizionato ben sotto la posizione 20 nel benchmark Polyglot (coding), con un punteggio intorno al 15%, contro il 72% di Gemini 2.5 Pro, il 60% di Claude Sonnet e il 55% di DeepSeek V3.
Un altro benchmark indipendente su problemi di teoria dei grafi NP-completi ha mostrato Maverick al decimo posto, superato anche da modelli molto più piccoli come Phi4 e Qwen 2.5 Coder 32B.
Come spiegare questa discrepanza? È possibile che Meta abbia selezionato attentamente i benchmark dove i suoi modelli brillano, evitando quelli dove le performance sono meno impressionanti. È una pratica comune nel settore, ma la differenza qui sembra particolarmente marcata.
La Context Window: Una Promessa Mantenuta?
Se c’è un aspetto in cui Llama 4 sembra davvero brillare, è la lunghezza della context window. Scout offre una finestra di contesto di 10 milioni di token, una cifra che fa impallidire i 128K dei modelli precedenti.
Meta ha mostrato risultati impressionanti nei test “needle-in-a-haystack”, dove il modello deve recuperare informazioni specifiche sepolte in enormi quantità di testo. I grafici mostrano una capacità di recupero quasi perfetta, anche con profondità di contesto del 100%.
Questo è un risultato notevole, se confermato. Una context window così ampia apre possibilità interessanti per analizzare documenti estremamente lunghi, codici sorgente complessi o persino interi libri in una singola query.
Tuttavia, anche qui alcuni tester indipendenti hanno sollevato dubbi. Alcuni utenti riferiscono che il modello sembra “dimenticare” il contesto in conversazioni molto lunghe, contraddicendo i risultati mostrati da Meta. È possibile che la performance degradi in scenari reali rispetto ai test controllati?
L’Addestramento: Un’Impresa Titanica con Risultati Discutibili
Il training di Llama 4 è stato un’impresa colossale. Meta riferisce di aver utilizzato 32.000 GPU, raggiungendo 390 teraflop per GPU, con un mix di training che include oltre 30 trilioni di token di testo, immagini e video.
Il modello è stato pre-addestrato con una context length nativa di 256K token, poi estesa a 10 milioni attraverso tecniche specializzate. Meta ha implementato una nuova architettura che chiama “iRoPE” (interleaved RoPE), con strati di attenzione alternati senza embedding posizionali.
Un aspetto interessante è la “codistillazione” usata per Maverick: il modello è stato distillato da Behemoth durante il pre-training, un approccio che dovrebbe trasferire le capacità del modello più grande al più piccolo.
Nonostante questi sforzi impressionanti, i risultati sembrano non essere all’altezza delle aspettative. Cosa è andato storto?
Le Sfide dell’Architettura MoE
I modelli MoE offrono grandi vantaggi teorici, ma l’addestramento efficace di questa architettura si è dimostrato notoriamente difficile. Il problema principale è bilanciare l’apprendimento tra i diversi esperti.
Se alcuni esperti vengono attivati più frequentemente di altri, si crea uno squilibrio: gli esperti popolari migliorano rapidamente, mentre quelli meno utilizzati rimangono sotto-addestrati. Questo può portare a un circolo vizioso, dove il router indirizza sempre più token verso gli esperti già ben addestrati.
DeepSeek è riuscita a superare questa sfida con il suo V3, ma sembra che Meta abbia incontrato più difficoltà. A mio avviso (ma è solo una supposizione) il training non è riuscito a convergere correttamente per qualche ragione, ma dopo aver speso così tanti soldi e tempo, hanno comunque deciso di rilasciare i modelli.
Multimodalità: Un Passo nella Direzione Giusta
Un aspetto in cui Llama 4 sembra fare progressi significativi è la multimodalità nativa. I modelli sono stati progettati con “early fusion” per integrare perfettamente token di testo e visivi in un backbone unificato.
Questo approccio consente un pre-addestramento congiunto con grandi quantità di dati di testo, immagini e video non etichettati. Meta ha anche migliorato l’encoder visivo, basandolo su MetaCLIP ma adattandolo specificamente per lavorare con l’LLM.
I benchmark su attività di comprensione delle immagini mostrano risultati decenti, con Scout che raggiunge 69.4 su MMMU e Maverick 73.4. Questi non sono i migliori risultati in assoluto, ma rappresentano un miglioramento rispetto ai precedenti modelli Llama.
Post-training e Allineamento
Meta descrive il suo approccio al post-training come un processo a più fasi:
- SFT (Supervised Fine-Tuning) leggero
- RL online (Reinforcement Learning)
- DPO (Direct Preference Optimization) leggero
Un dettaglio interessante è che hanno rimosso più del 50% dei dati considerati “facili” utilizzando i modelli Llama stessi come giudici. Questa curation aggressiva dei dati di training è una tendenza crescente nel settore: la qualità dei dati spesso conta più della quantità.
Per quanto riguarda le protezioni e i rischi, Meta afferma di aver integrato mitigazioni a ogni livello dello sviluppo del modello e offre strumenti open source come Llama Guard, Prompt Guard e CyberSecEval per aiutare gli sviluppatori a gestire i rischi.
Il Caso Llama 4 nel Contesto Più Ampio
La situazione di Llama 4 solleva questioni più ampie sull’attuale stato dell’IA in Meta. Recentemente, Joelle Pineau, vicepresidente della ricerca IA di Meta, ha annunciato le sue dimissioni. Questo potrebbe indicare problemi più profondi all’interno dell’organizzazione.
C’è anche una crescente sensazione che Meta stia perdendo terreno rispetto ad altri laboratori di ricerca. Tra i principali attori con risorse simili (OpenAI, Anthropic, Google, DeepSeek e X), Meta sembra produrre i modelli meno competitivi, suggerendo possibili problemi strutturali nella divisione IA dell’azienda.
In prospettiva, questa situazione potrebbe portare a cambiamenti significativi nella strategia IA di Meta nei prossimi mesi.
Aspetti Tecnici per gli Sviluppatori
Per chi è interessato agli aspetti più tecnici, ecco alcuni dettagli aggiuntivi sui modelli:
Llama 4 Scout:
- 17B parametri attivi, 16 esperti, 109B parametri totali
- Context window: 10M token
- Pre-training nativo a 256K context length
- Supporto multimodale con comprensione di immagini
Llama 4 Maverick:
- 17B parametri attivi, 128 esperti, 400B parametri totali
- Context window: 1M token
- Codistillato da Behemoth durante il pre-training
- Costo di inferenza stimato: $0.19-$0.49 per 1M token (input+output)
Llama 4 Behemoth:
- 288B parametri attivi, 16 esperti, 2T parametri totali
- Non ancora rilasciato pubblicamente
- Usato principalmente come modello insegnante
- Supera GPT-4.5 e Claude Sonnet 3.7 su diversi benchmark STEM
Tutti i modelli utilizzano un’architettura che alterna livelli densi e MoE, con un esperto condiviso per tutti i token e routing specializzato per gli esperti individuali.
Chi Dovrebbe Usare Llama 4?
Nonostante le criticità, Llama 4 potrebbe ancora essere utile in alcuni scenari:
Applicazioni che necessitano di context window estremamente lunghe: Se hai bisogno di analizzare documenti molto lunghi in un singolo passaggio, Scout con la sua finestra di contesto di 10M potrebbe essere una scelta valida.
Deployment in ambienti con risorse limitate: L’architettura MoE permette di attivare solo una frazione dei parametri totali durante l’inferenza, rendendo i modelli più efficienti in termini di risorse computazionali.
Applicazioni multimodali semplici: Per compiti base di comprensione delle immagini, i modelli sono sufficientemente capaci.
Tuttavia, per applicazioni critiche che richiedono ragionamento complesso, risoluzione di problemi o generazione di codice avanzato, altri modelli come Claude Sonnet 3.7, GPT-4.5 o DeepSeek V3 potrebbero essere scelte più affidabili.
Prospettive Future per Llama
Il futuro della famiglia Llama dipenderà da come Meta risponderà alle attuali sfide. Ecco alcuni possibili sviluppi:
Miglioramenti incrementali: È probabile che vedremo aggiornamenti di Llama 4 nei prossimi mesi, man mano che Meta risolve i problemi di addestramento e migliora l’equilibrio tra gli esperti.
Rilascio di Behemoth: Se il modello insegnante è davvero competitivo come suggeriscono i benchmark interni, il suo eventuale rilascio potrebbe cambiare la percezione della linea Llama 4.
Ripensamento strategico: Le delusioni attuali potrebbero portare a un ripensamento dell’approccio di Meta all’IA, possibilmente con cambiamenti nella leadership e nella direzione della ricerca.
Focalizzazione sulle context window: Meta potrebbe capitalizzare sul vantaggio in termini di lunghezza di contesto, perfezionando questo aspetto dei loro modelli anche a scapito di altre capacità.
Conclusioni: Un Passo Avanti, Due Indietro?
Llama 4 rappresenta un esperimento ambizioso nell’architettura MoE e nell’estensione della context window. Nonostante l’enorme impegno in termini di risorse computazionali e ingegneristiche, i risultati reali sembrano deludenti rispetto alle promesse iniziali.
Questa discrepanza tra marketing e prestazioni effettive solleva questioni importanti sulla trasparenza nel settore dell’IA. È essenziale che i ricercatori indipendenti continuino a testare e valutare i modelli, per fornire un controllo esterno alle affermazioni delle aziende.
In definitiva, Llama 4 potrebbe essere ricordato non tanto per i suoi successi, ma per le lezioni che insegna: l’architettura MoE è potente ma difficile da padroneggiare, la context window lunga è un vantaggio significativo, e la trasparenza nei benchmark è fondamentale per la credibilità.
Per noi sviluppatori e appassionati di tecnologia, il messaggio è chiaro: è sempre importante guardare oltre il marketing e testare personalmente le tecnologie prima di integrarle nei nostri progetti. Nel frattempo, continueremo a monitorare l’evoluzione di Llama 4 e gli sviluppi futuri nella divisione IA di Meta.
Che ne pensi di Llama 4? Hai avuto modo di testarlo? Condividi la tua esperienza nei commenti!